Hortonworks Software Engineers Vinod Kumar Vavilapalli (Apache Hadoop YARN committer) and Jian He (Apache YARN Hadoop committer) discuss Apache Hadoop YARN’s Resource Manager resiliency upon restart in this blog.This is their third blog post in our series on motivations and architecture for improvements to the Apache Hadoop YARN’s Resource Manager (RM) resiliency. Others in the series are:
- Introduction: Apache YARN Resource Manager Resiliency
- Resilience of Apache Hadoop YARN Applications across ResourceManager Restart – Phase 1
Introduction
Phase II – Preserving work-in-progress of running applications
ResourceManager-restart is a critical feature that allows YARN applications to be able to continue functioning even when the ResourceManager (RM) crash-reboots due to various reasons. In the previous post, we gave an overview of the RM-restart mechanism:
- how it preserves application queues as part of the Phase I implementation
- how user-land applications or frameworks are impacted, and the related configurations.
As we discussed, RM-restart Phase I sets up the groundwork for RM restart Phase II (preserving work-in-progress) and RM High Availability, the first of which we’ll explore in this post.
The effort for Phase II (a feature in progress at the time of this post) focuses on making the YARN reconstruct the entire running-state of the cluster as it was before the restart together with the corresponding applications. By taking advantage of the recovered application-queues from Phase I, RM-restart Phase II further improves the resiliency by combining persisted application metadata with information about container-statuses from all the NodeManagers, with the outstanding allocation-requests from the running ApplicationMasters (AMs) in the cluster. The end-result is that applications do not lose any running or completed work due to a RM crash-reboot event, and no restart of applications or containers is required, as the ApplicationMasters will just re-sync with the newly started RM.
This effort is tracked in its entirety under the JIRA ticket YARN-556.
Architecture
As one can imagine, the challenge in this effort comes from state-management: RM has to remember enough information during its regular control flow and then subsequently piece that together with the rest of the cluster-state after a restart. The following is a rough outline of what the cluster remembers and what it doesn’t:
- List of all the applications that ever were submitted to a YARN cluster: remembered on state-store
- Metadata—Submission context, application-attempt level information, and credentials—about each application so that it can be executed as usual after RM restart: remembered on state-store
- State of allocated and outstanding containers of each application: not remembered. Container allocations happen so often in a YARN cluster that it is not feasible for ResourceManager to remember all of them. Instead, ResourceManager reconstructs all of the state after restart from the heartbeats of the nodes and the ApplicationMasters.
- Overall cluster state—list of nodes that are active, decommissioned or lost : remembered on state-store. This is needed to give applications a sane view of the cluster, with respect to scheduling, available capacity etc, once RM restarts. Otherwise, suddenly after RM-restart, each application may see a very “small cluster.”
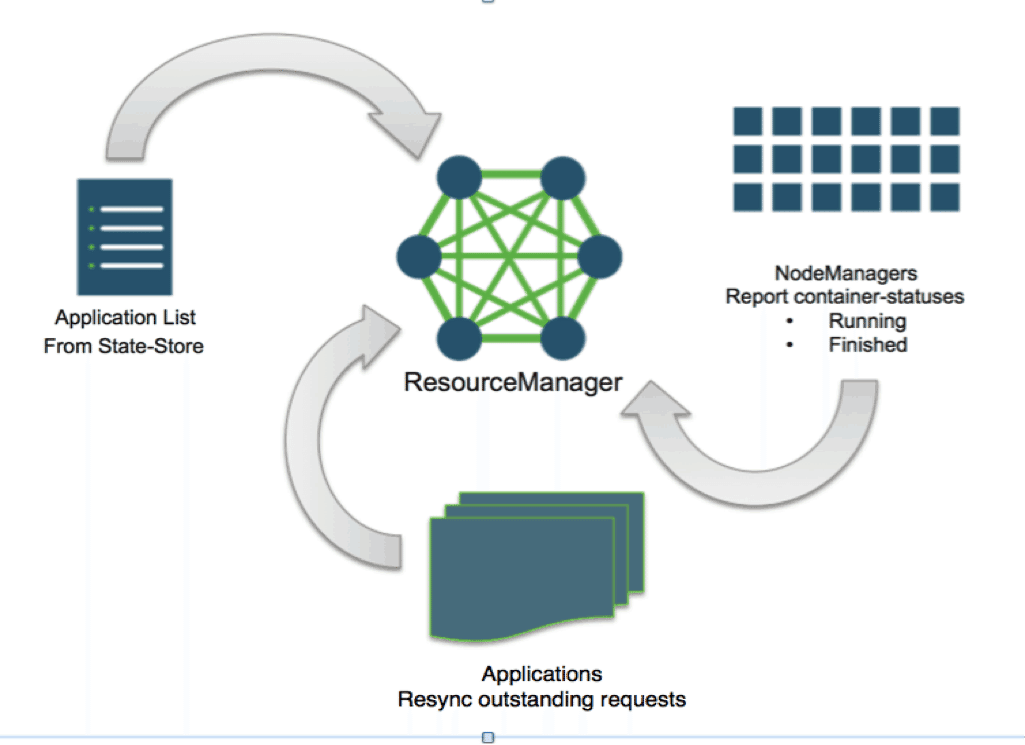
Next, we describe the architecture and implementation: how each of the YARN components is involved in enabling the feature of preserving work-in-progress across ResourceManager restart.
ResourceManager
The majority of the work in ResourceManager is to reconstruct the running state of the scheduler in the ResourceManager.
As covered in the RM-restart Phase I post, ResourceManager persists the application-queue state in an underlying state-store at runtime and reloads the same state into memory when it restarts. This application-queue state only contains the metadata of the applications (e.g. ApplicationSubmissionContext), but does not include any running state of the ResourceManager—for example, the state of the central scheduler inside ResourceManager that keeps track of the dynamically changing queue resource-usage, all containers’ life-cycle and applications’ resource-requests, headrooms etc. All this information will be erased once RM shuts down. This is the reason why in Phase I, ResourceManager cannot accept resource-requests from previously running ApplicationMasters after ResourceManager reboots, so it has to spawn a new application-attempt to start the ApplicationMaster from a clean state.
Persisting all of the scheduler state as well as the application-queue state in the state-store all the time is not efficient, because the scheduler’s state changes too fast. To avoid persisting massive amount of data, we restore the state of the scheduler by absorbing the container-statuses reported by the NodeManagers, which have the necessary information to recover the containers.
After ResourceManager reboots and reloads the applications from the state-store, it starts receiving the container statuses from NodeManagers and passes that information to the scheduler. Based on the information passed from the previously running container-statuses, the scheduler first creates a new container in-memory representation. Next, it associates the new container with the corresponding applications and queues. This is done in such a way that the code paths for regular container allocation and this special container-recovery workflow are the same. As a result, the scheduler also updates scheduling information such as applications’ used-resources, headrooms, queue-metrics etc. Note that today, reserved containers—that is, the containers that are reserved for fulfilling application resource-requests—cannot be recovered as NodeManagers lack such information to send back to the ResourceManager.
To avoid the scheduler from prematurely starting to allocate new containers before the recovery process is settled, scheduler is augmented with some configurations to prevent allocating new containers until some kind of threshold is met, such as a configured amount of wait time or a certain percentage of previous nodes that have joined with new ResourceManager. Once the threshold is met, scheduler starts accepting new resource-requests and allocates new containers as before.
Node Manager
Here’s what happens at any NodeManager in a cluster during and after a RM-restart event in the cluster:
- During the downtime of ResourceManager, NodeManagers manage the containers as usual and keep retrying with RM. Existing containers will run as usual and may even finish. Status of any finished containers is remembered as usual till NM can report them back to the ResourceManager.
- After ResourceManager restarts, it sends every NodeManager a resync command once a NM-heartbeat comes in. In Phase I, NMs reacted to such a resync command by killing all the running containers (in the process losing work-in-progress) and re-registering with RM with a fresh state. After Phase II, NMs are changed to not kill existing running containers so that the applications can preserve their work-in-progress across RM restart. After that, NMs re-register with RM and send the container-statuses across the cluster—this includes containers that are still running as well as those that may have finished in the interim.

ApplicationMaster
After restart, RM loads the application state from the state-store. In Phase I, the rebooted RM then notifies the NMs to kill all their containers including the ApplicationMaster container. Essentially, all previously running application attempts are killed in this manner. In the meanwhile, RM pauses the application life-cycle until the previous AM container exits and then spins off a new AM container. From RM’s perspective, this is similar to AM failure and retry.
This completely changes in Phase II. A quick outline of the control flow follows:
- As mentioned before, NMs will no longer simply kill all their managed containers in case of a RM restart. Thus, AM container (and, therefore, the application itself) continues running and keeps retrying the communication with RM in a similar way NMs do.
- During this period, AM continues operating with its own application work but will not able to request new containers from the RM.
- Since the restarted RM loses the fact that an AM had previously registered, the AM must re-register itself, otherwise the scheduling protocol will throw an ApplicationMasterNotRegisteredException.
- Note that AM could have sent resource-requests to the RM, but RM may have shut down before the resource-requests were fulfilled by the scheduler. This causes any outstanding resource-requests to be lost. Therefore, the AM must re-send the previously unfulfilled resource-requests to the newly restarted RM.
For most of the applications that already use the scheduling client library (AMRMClient), the library itself will take care of most of the above things. The client library is augmented to keep track of any of the outstanding requests and re-send those requests via the first allocate call to the newly active RM. Application writers using AMRMClient to communicate with RM do not need to write extra logic to handle the flow that is invoked during RM restart.
Note that even in regular life-cycle, users should act on successful allocations and are required to call the removeContainerRequest() API to inform the library and the ResourceManager about any changes in the locality requirements. If users ignore to inform ResourceManager, it may not understand the latest state of locality requirements. This situation is further exacerbated during AM resync, in which the library will send stale requests to the ResourceManager.

Current state of the project
At the time of this writing, the most significant task of core changes to reload the scheduler state is already done in YARN-1368. The other important changes to close the loop are running fast toward completion (YARN-1367 and YARN-1366). We are tracking the delivery of the project to be targeted for one of the next Apache Hadoop releases.
Conclusion
In this blog post, we described RM-restart Phase II, a feature to enable applications to continue functioning while preserving work-in-progress across RM-restart. In contrast with Phase I, no application’s in-flight work will be interrupted on RM restart.
Another related feature, ResourceManager Failover, improves ResourceManger resiliency further by providing an ability for ApplicationMasters and NodeManagers to redirect and resync to a “new” ResourceManger as soon as the current active ResourceManager fails over.
That will be the topic for the next post.
The post Resilience of Apache Hadoop YARN Applications across ResourceManager Restart – Phase 2 appeared first on Hortonworks.