This post is the seventh in our series on the motivations, architecture and performance gains of Apache Tez for data processing in Hadoop. The series has the following posts:
- Apache Tez: A New Chapter in Hadoop Data Processing
- Data Processing API in Apache Tez
- Runtime API in Apache Tez
- Writing a Tez Input/Processor/Output
- Apache Tez: Dynamic Graph Reconfiguration
- Reusing containers in Apache Tez
- Introducing Tez Sessions
In Tez, we recently introduced the support of a feature that we call “Tez Sessions”.
Most relational databases have had a notion of sessions for quite some time. A database session can be considered to represent a connection between a user/application and the database or in more general terms, an instance of usage of a database. A session can encompass multiple queries and/or transactions. It can leverage common services, for example, caching, to provide some level of performance optimizations.
A Tez session, currently, maps to one instance of a Tez Application Master (AM). For folks who are familiar with YARN and MapReduce, you would know that for each MapReduce job, a corresponding MapReduce Application Master is launched. In Tez, using a Session, a user can can start a single Tez Session and then can submit DAGs to this Session AM serially without incurring the overhead of launching new AMs for each DAG.
Motivation for Tez Sessions
As mentioned earlier, the main proponents for Tez are Apache projects such as Hive and Pig. Consider a Pig script, the amount of work programmed into a script may not be doable within a single Tez DAG. Or let us take a common data analytics use-case in Hive where a user uses a Hive Shell for data drill-down (for example, multiple queries over a common data-set). There are other more general use-cases such as users of Hive connecting to the Hive Server and submitting queries over the established connection or using the Hive shell to execute a script containing one or more queries.
All of the above can leverage Tez Sessions.
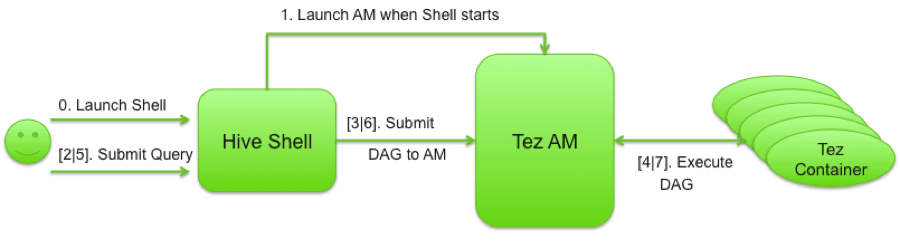
Using Tez Sessions
Using a Tez Session is quite simple:
- Firstly, instantiate a
TezSessionobject with the required configuration usingTezSessionConfiguration. - Invoke
TezSession::start() - Wait for the TezSession to reach a ready state to accept DAGs by using the
TezSession::getSessionStatus()api (this step is optional) - Submit a DAG to the Session using
TezSession::submitDAG(DAG dag) - Monitor the DAG’s status using the
DAGClientinstance obtained in step (4). - Once the DAG has completed, repeat step (4) and step (5) for subsequent DAGs.
- Shutdown the Session once all work is done via
TezSession::stop().
There are some things to keep in mind when using a Tez Session:
- A Tez Session maps to a single Application Master and therefore, all resources required by any user-logic (in any subsequent DAG) running within the ApplicationMaster should be available when the AM is launched.
- This mostly pertains to code related to the VertexOutputCommitter and any user-logic in the Vertex scheduling and management layers.
- User-logic run in tasks is not governed by the above restriction.
- The resources (memory, CPU) of the AM are fixed so please keep this in mind when configuring the AM for use in a session. For example, memory requirements may be higher for a very large DAG.
Performance Benefits of using Tez Sessions
Container Re-Use. We know that re-use of containers was doable within a single DAG. In a Tez Session, containers are re-used even across DAGs as long as the containers are compatible with the task to be run on them. This vastly improves performance by not incurring the overheads of launching containers for subsequent DAGs. Containers, when not in use, are kept around for a configurable period before being released back to YARN’s ResourceManager.
Caching with the Session. When running drill-down queries on common datasets, smarting caching of meta-data and potentially even caching of intermediate data or previous results can help improve performance. Caching could be done either within the AM or within launched containers. Such caching allows for more fine-grained controls with respect to caching policies. A session-based cache as compared to a global cache potentially provides more predictable performance improvements.
Example Usage of a Tez Session
The Tez source code has a simple OrderedWordCount example. This DAG is similar to the WordCount example in MapReduce except that it also orders the words based on their frequency of occurrence in the dataset. The DAG is an MRR chain i.e. a 3-vertex linear chain of Map-Reduce-Reduce.
To run the OrderedWordCount example to process different data-sets via a single Tez Session, use:
bin/hadoop jar tez-mapreduce-examples-0.2.0-
Below is a graph depicting the times seen when running multiple MRR DAGs on the same dataset (the dataset had 6 files to ensure multiple containers are needed in the map stage ) in the same session. This test was run on my old MacBook running a single node Hadoop cluster having only one DataNode and one NodeManager.
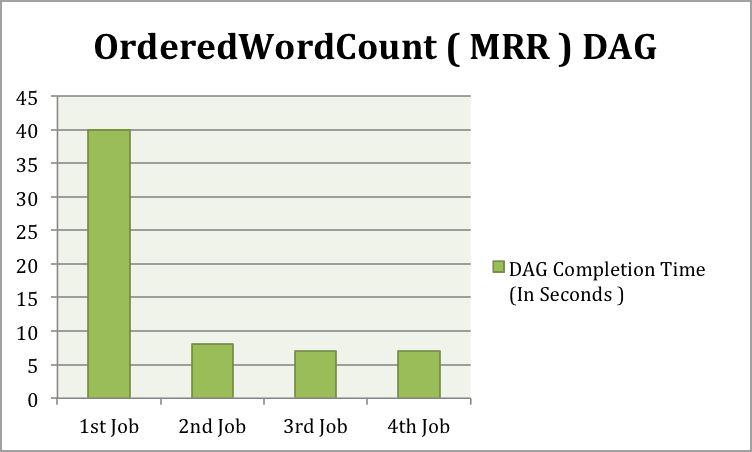
As you can see, even though this is just a simulation test running on a very small data set, leveraging containers across DAGs has a huge performance benefit.
The post Introducing Tez Sessions appeared first on Hortonworks.