The power of a well-crafted speech is indisputable, for words matter—they inspire to act. And so is the power of a well-designed Software Development Kit (SDK), for high-level abstractions and logical constructs in a programming language matter—they simplify to write code.
In 2007, when Chris Wensel, the author of Cascading Java API, was evaluating Hadoop, he had a couple of prescient insights. First, he observed that finding Java developers to write Enterprise Big Data applications in MapReduce will be difficult and convincing developers to write directly to the MapReduce API was a potential blocker. Second, MapReduce is based on functional programing elements.
With these two insights, Wensel designed the Java Cascading Framework, with the sole purpose of enabling developers to write Enterprise big data applications without the know-how of the underlying Hadoop complexity and without coding directly to the MapReduce API. Instead, he implemented high-level logical constructs, such as Taps, Pipes, Sources, Sinks, and Flows, as Java classes to design, develop, and deploy large-scale big data-driven pipelines.
Sources, Sinks, Traps, Flows, and Pipes == Big Data Application
At the core of most data-driven applications is a data pipeline through which data flows, originating from Taps and Sources (ingestion) and ending in a Sink (retention) while undergoing transformation along a pipeline (Pipes, Traps, and Flows). And should something fail, a Trap (exception) must handle it. In the big data parlance, these are aspects of ETL operations.
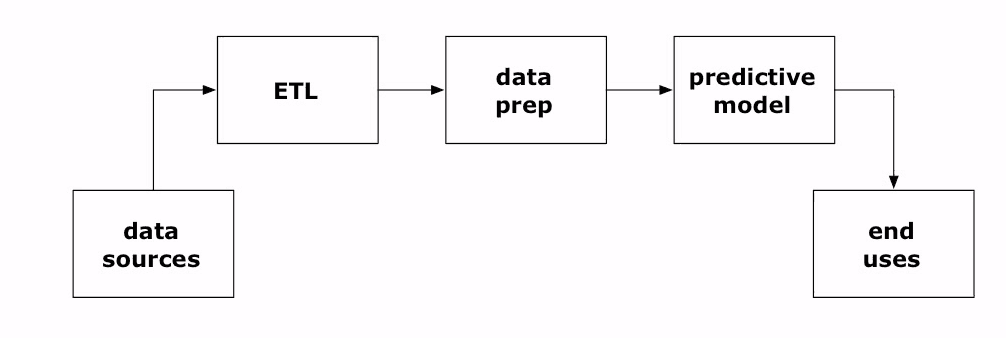
The Cascading SDK embodies these plumbing metaphors and provides equivalent high-level Java constructs and classes to implement your sources, sinks, traps, flows, and pipes. These constructs enable a Java developer eschew writing MapReduce jobs directly and design his or her data flow easily as a data-driven journey: flowing from a source and tap, traversing data preparation and traps, undergoing transformation, and, finally, ending up into a sink for user consumption.
Now, I would be remiss without showing the WordCount example, the equivalent of the Hadoop Hello World, to illustrate how these constructs translate into MapReduce jobs, without understanding the underlying complexity of the Hadoop ecosystem. That simplicity is an immediate and immense draw for a Java developer to write data-driven Enterprise applications at scale on top of the underlying Hortonworks Data Platform (HDP 2.1). And the beauty of this simplicity is that your entire data-driven application can be compiled as a jar file, a single unit of execution, and deployed onto the Hadoop cluster.
So let’s explore the wordcount example, which can be visualized as a pattern of data flowing through a pipeline under going transformation, beginning from a source (Document Collection) and ending into a sink (Word Count).
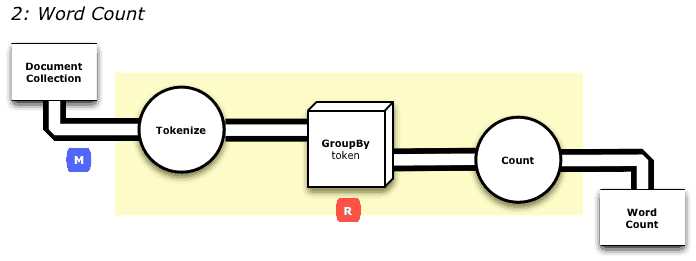
In a single file, Main.java, I can code my data pipeline into a MapReduce program using Cascade’s high-level constructs and Java classes. For example, below is a complete source listing for the above transformation.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 | package impatient; import java.util.Properties; import cascading.flow.Flow; import cascading.flow.FlowDef; import cascading.flow.hadoop.HadoopFlowConnector; import cascading.operation.aggregator.Count; import cascading.operation.regex.RegexFilter; import cascading.operation.regex.RegexSplitGenerator; import cascading.pipe.Each; import cascading.pipe.Every; import cascading.pipe.GroupBy; import cascading.pipe.Pipe; import cascading.property.AppProps; import cascading.scheme.Scheme; import cascading.scheme.hadoop.TextDelimited; import cascading.tap.Tap; import cascading.tap.hadoop.Hfs; import cascading.tuple.Fields; public class Main { public static void main( String[] args ) { String docPath = args[ 0 ]; String wcPath = args[ 1 ]; Properties properties = new Properties(); AppProps.setApplicationJarClass( properties, Main.class ); HadoopFlowConnector flowConnector = new HadoopFlowConnector( properties ); // create source and sink taps Tap docTap = new Hfs( new TextDelimited( true, "\t" ), docPath ); Tap wcTap = new Hfs( new TextDelimited( true, "\t" ), wcPath ); // specify a regex operation to split the "document" text lines into a token stream Fields token = new Fields( "token" ); Fields text = new Fields( "text" ); RegexSplitGenerator splitter = new RegexSplitGenerator( token, "[ \\[\\]\\(\\),.]" ); // only returns "token" Pipe docPipe = new Each( "token", text, splitter, Fields.RESULTS ); // determine the word counts Pipe wcPipe = new Pipe( "wc", docPipe ); wcPipe = new GroupBy( wcPipe, token ); wcPipe = new Every( wcPipe, Fields.ALL, new Count(), Fields.ALL ); // connect the taps, pipes, etc., into a flow FlowDef flowDef = FlowDef.flowDef() .setName( "wc" ) .addSource( docPipe, docTap ) .addTailSink( wcPipe, wcTap ); // write a DOT file and run the flow Flow wcFlow = flowConnector.connect( flowDef ); wcFlow.writeDOT( "dot/wc.dot" ); wcFlow.complete(); } } |
First, we create a Source (docTap) and a Sink (wcTap) with two constructors, new Hfs(…). The RegexSplitGenerator() class defines the semantics for a Tokenizer (see diagram above).
Second, we create two Pipe(s), one for the tokens and the other for word count. To the word count Pipe, we attach aggregate semantics how we want our tokens to be grouped by using a Java construct GroupBy.
Once we have two Pipes, we connect them into a Flow by defining a FlowDef and using the HadoopFlowConnector.
And finally, we connect the pipes and run the flow. The result of this execution is a MapReduce job that runs on HDP. (The dot file is a by-product and maps the flow; it’s a good debugging tool to visualize the flow.)
Note that nowhere in the code is there any reference to mappers and reducers’ interface. Nor is there any indication of how the underlying code is translated into mappers and reducers and submitted to Tez or YARN.
As UNIX Bourne shell commands are building blocks to a script developer, so are the Cascading Java classes for a Java developer—they provide higher-level functional blocks to build an application; they hide the underlying complexity.
For example, a command strung together as “cat document.tweets | wc -w | tee -a wordcount.out” is essentially a data flow, similar to the one above. A developer understands the high-level utility of the commands, but is shielded from how the underlying UNIX operating system translates the commands into a series of forks(), execs(), joins(), and dups() and how it joins relative stdin and stdout of one program to another.
In a similar way, the Cascading Java building blocks are translated into MapReduce programs and submitted to the underlying big data operating system, YARN, to handle any parallelism and resource management on the cluster. Why force the developer to code directly to MapReduce Java interface when you can abstract it with building blocks, when you can simplify to write code easily?
What Now?
The output of this program run is shown below. Note how the MapReduce jobs are submitted as a client to YARN.
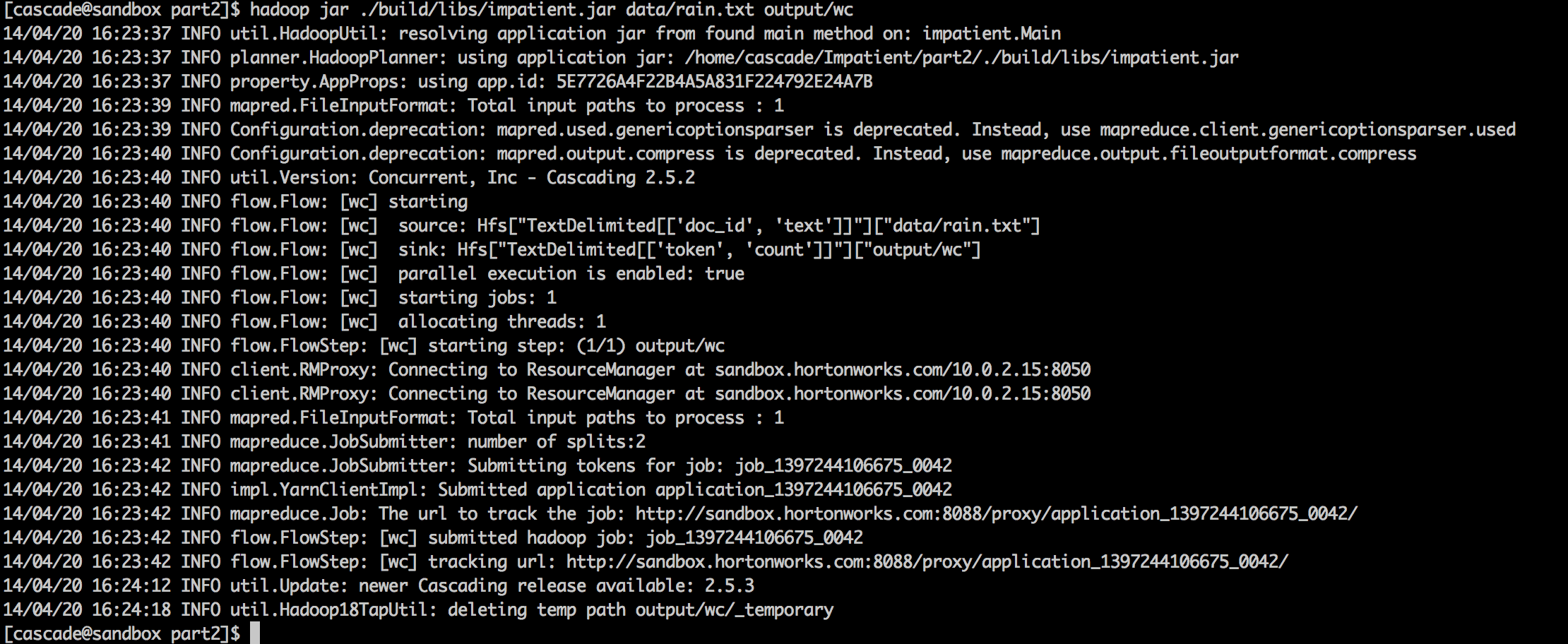
Even though the example presented above is simple, the propositions from which the Cascading SDK was designed—high-level Java abstractions to shield the underlying complexity, functional programming nature of MapReduce programs, and inherent data flows in data-driven big data applications—demonstrate the simplicity and the ability to easily develop data-driven applications and deploy them at scale on HDP while taking advantage of underlying Tez and YARN.
As John Maeda said, “Simplicity is about living life with more enjoyment and less pain,” so why not embrace programming frameworks that deliver that promise—more enjoyment, easy coding, increase in productivity, and less pain.
What’s Next?
Associated with The Cascading SDK are other projects such as Lingual, Scalding, Cascalog, and Pattern. Together, they provide a comprehensive data application framework to design and develop Enterprise data-driven applications at scale on top of HDP 2.1.
To dabble your feet and whet your appetite, you can peruse Cascading’s tutorials on each of these projects.
For hands-on experience on HDP 2.1 Sandbox for the above example, which is derived from part 2 of the Cascading’s Impatient series, you can follow this tutorial.
The post How To Get Started with Cascading and Hadoop on Hortonworks Data Platform appeared first on Hortonworks.