With the attention of the Hadoop community on Strata/Hadoop World in New York this week, it’s seems an appropriate time to give everyone an early update on continued community development of Apache Hive. This progress well and truly cements Hive as the standard open-source SQL solution for the Apache Hadoop ecosystem for not just extremely large-scale, batch queries but also for low-latency, human-interactive queries.
You can catch me at our session ‘Apache Hive & Stinger: Petabyte Scale SQL, IN Hadoop’ along with Owen and Alan where we’ll be happy to dive into more of the details. It’s on 30th Oct, at 11:50am, Gramercy Suite B.
Many of you have heard of Project Stinger already, but for those who have not, Stinger is a community-facing roadmap laid out to improve Hive’s performance 100x and bring true interactive query to Hadoop. You can read more at www.hortonworks.com/labs/stinger.
We’ve gotten really excited lately as we’ve started to piece together the performance gains brought on by the past 9 months of hard work, including more than 700 closed Hive JIRAs and the launch of Apache Tez, which moves Hadoop beyond batch into a truly interactive big data platform.
Query Performance
Let’s start with an update of queries we first reported back in March of this year during Stinger Phase 1.
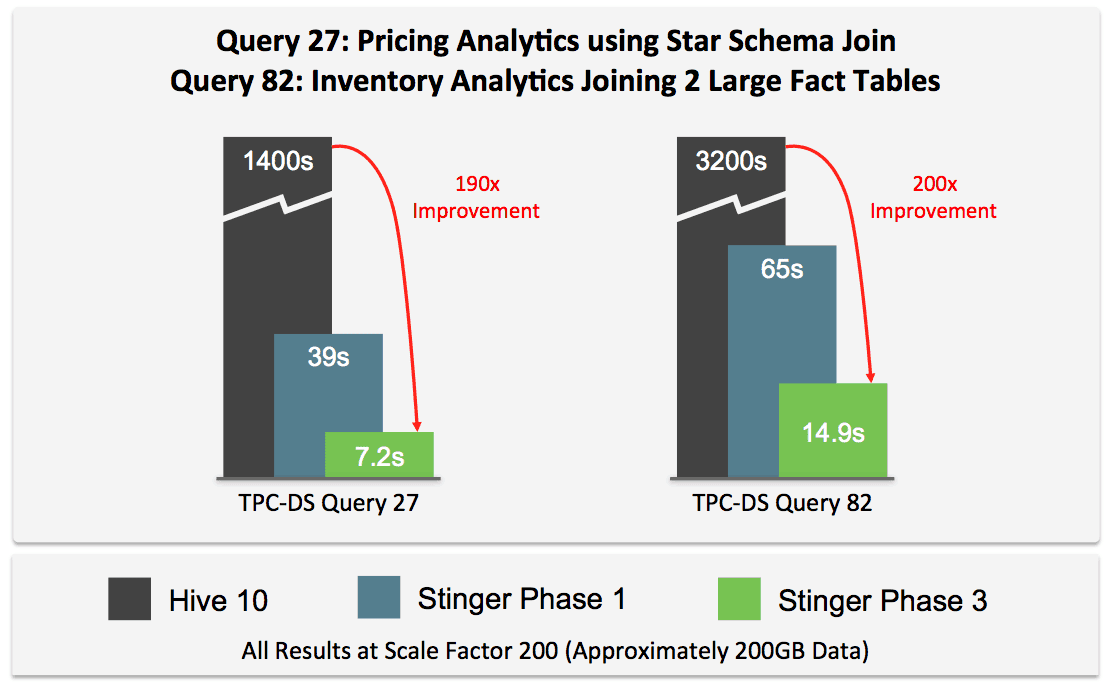
We’re very excited to see the progress Hive has made toward becoming a truly interactive SQL system built entirely in Hadoop.
As a benchmark, TPC-DS does a great job simulating decision support around retail operations, but it’s certainly not the only benchmark around. One benchmark that takes a more web-centric view is the Berkeley AMPLab Big Data Benchmark, which defines queries that range from simple filters to more complex revenue analytics.
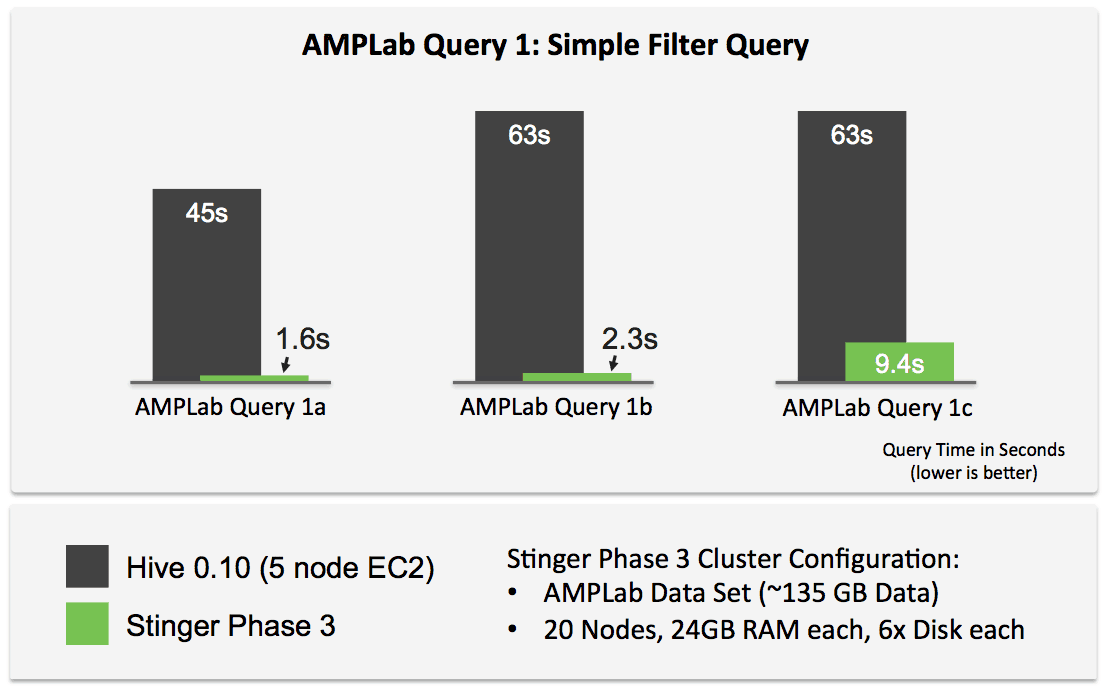
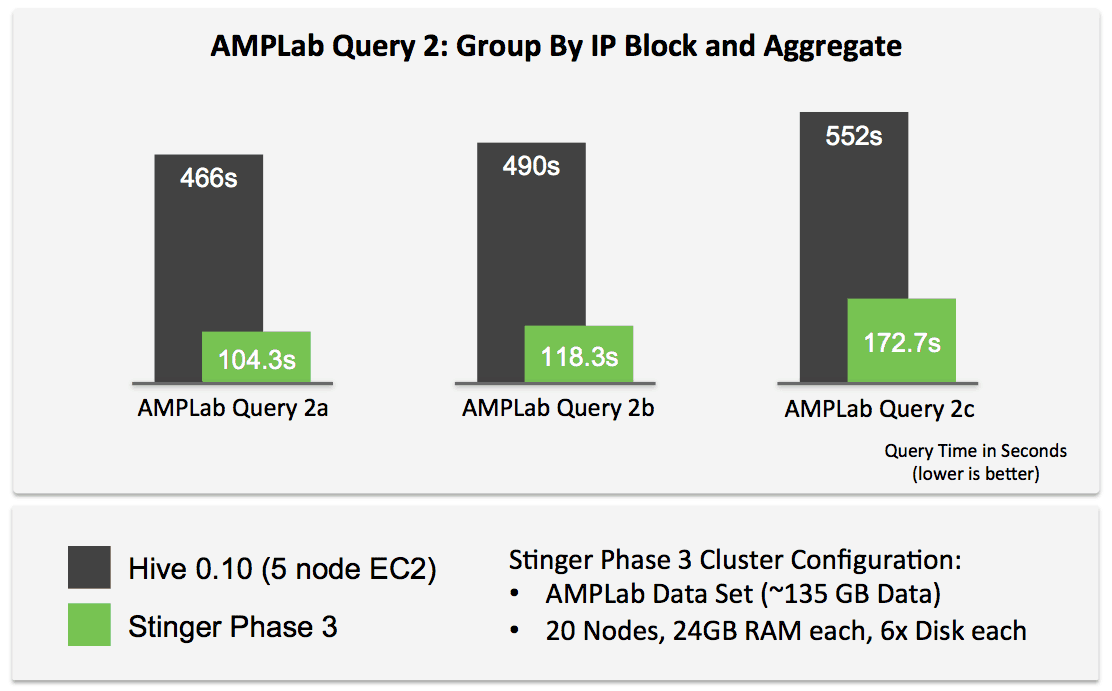
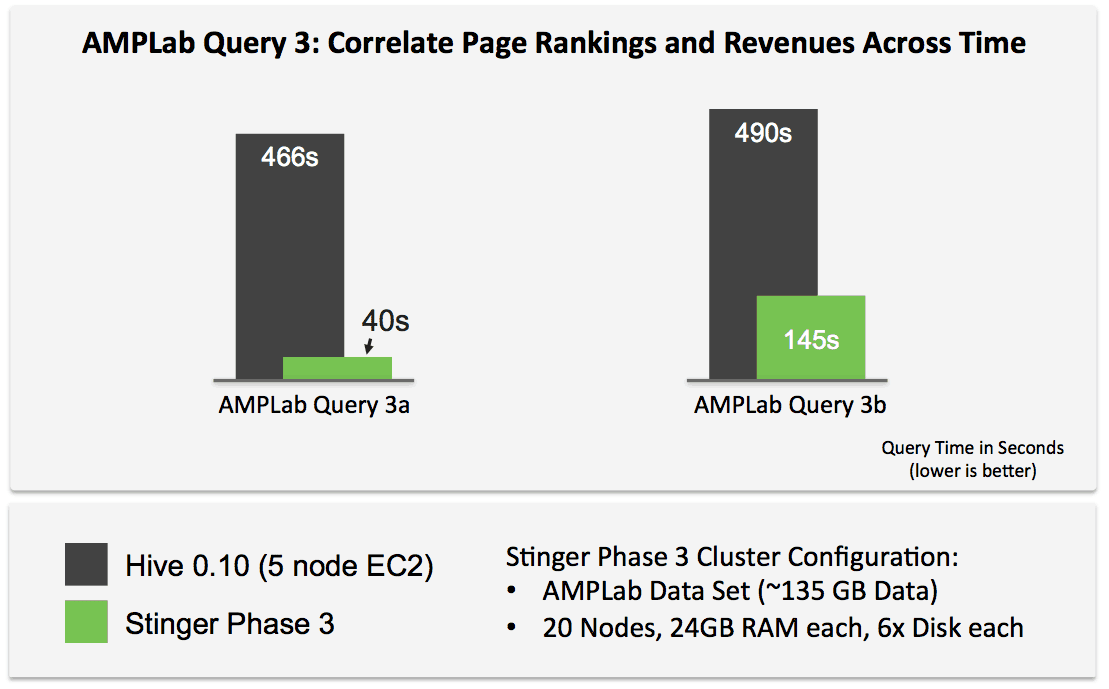
This isn’t an apples-to-apples comparison since we can’t run hive-0.10 on ORC etc., but the key point here is that with upcoming hive-0.13, we get very low latency SQL queries with Hive using Apache Tez.
Interactive Query, In Hadoop
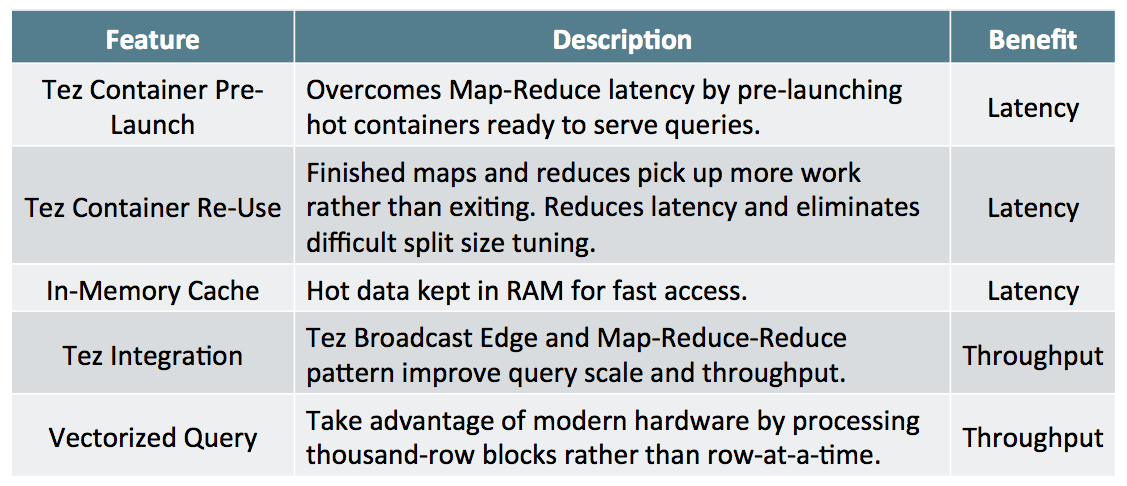
Historically, even simple Hive queries could not run in less than 30 seconds, yet many of these queries are running in less than 10 seconds. How did that happen? The answer mainly boils down to Apache Tez and Apache Hadoop YARN, which proves that Hadoop is more than just batch. Tez features such as container pre-launch and re-use overcome Hadoop’s traditional latency barriers, and are available to any data processing framework running in Hadoop.
Here’s a list of Stinger Phase 3 features and how they contribute to making Hadoop truly interactive:
Looking Ahead
We’ve mentioned before that we will be releasing Stinger 3 Beta in Q4 and are still working steadily to that goal. For everyone excited to take a look at Interactive Query in Hadoop using Hadoop’s de-facto SQL engine, you’ll be able to try it out for yourself soon.
Join us on 10/30 at 11:50am, Gramercy Suite B for ‘Apache Hive & Stinger: Petabyte Scale SQL, IN Hadoop’
The post Delivering on Stinger: a Phase 3 Progress Update appeared first on Hortonworks.